Background: We created a generative artificial intelligence chatbot (“VLRChat”) that draws from a comprehensive curricular resource (the 480-page Vanderbilt Housestaff Handbook) to answer point-of-care clinical questions by hospitalists and inpatient clinical teams. Time constraints and cognitive overload frequently prevent hospitalist faculty and learners from determining the optimal, most current answers to clinical questions: as many as 50% of clinical questions go unanswered (3,4). Large language models (LLMs) have demonstrated remarkable capabilities in complex problem solving, reasoning, and synthesis of documents to answer clinical questions, but few studies have evaluated authentic clinical questions or integrated into the workflow of hospitalists. We present the aims, design, and preliminary human evaluation of VLRChat, and share results from analysis of an initial test dataset of 180 clinical question-answer pairs.
Purpose: VLRChat aims to provide trustworthy, reliable, and accurate responses to point-of-care clinical questions. Integrating content from our own internal medicine residency’s handbook (“VIMBook”), VLRChat’s responses provide systems-based educational decision support at Vanderbilt and the Nashville VA. The handbook, updated and reviewed annually by dozens of residents and faculty, averages 55,000 visits to its website per month (1,2).
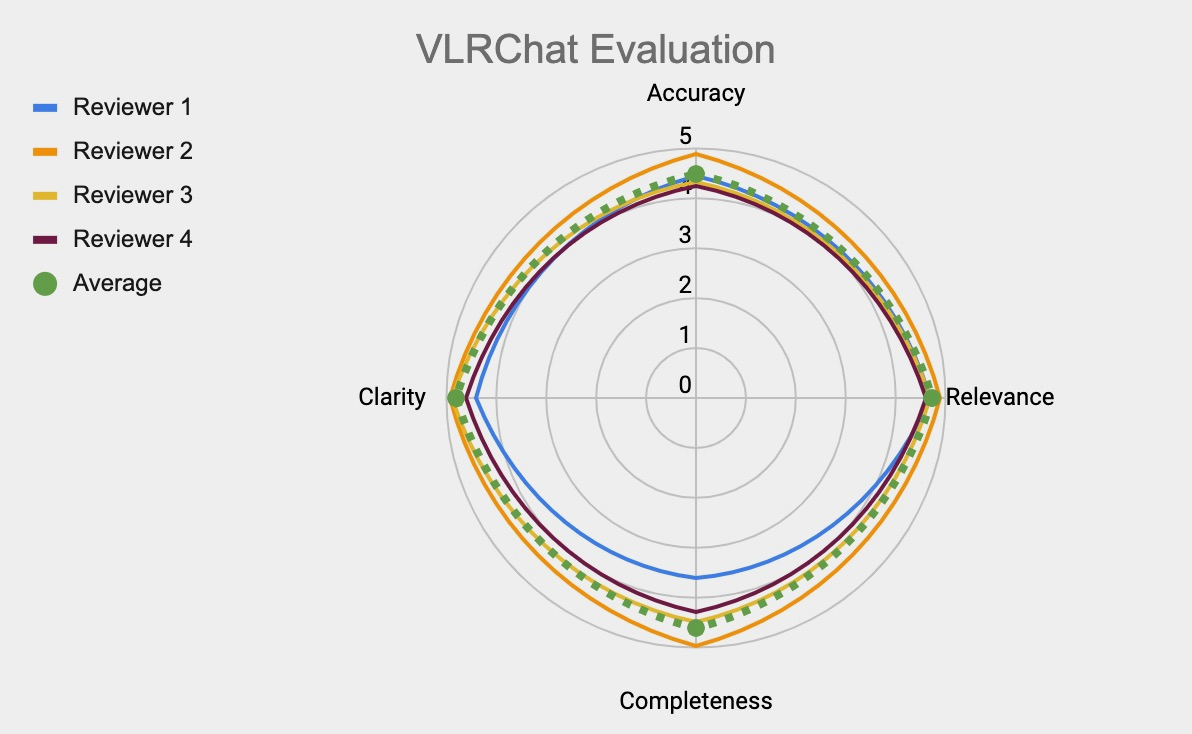
Description: VLRChat unites several components in an architecture that includes a large language model framework augmented with retrieval capabilities from a curated medical resource (Figure 1). Users input (1) a text query, the tool searches (2) the context of a digitized vector database version of VIMBook, and VLRChat engages (3) the user-selected LLM. VLRChat then responds (4) with synthesized answers, cites relevant chapters, and user provides (5) immediate feedback. An initial test set of 180 clinical questions (authentic, non-PHI containing) was developed by our research team (two medical students, one fellow, four board-certified hospitalists). We tasked a subset of this group (two students, two hospitalists) with evaluating VLRChat on domain axes for accuracy, relevance, completeness, and clarity. Human evaluators rated the 150/180 question-answer pairs successfully answered by VLRChat highly for accuracy (4.5/5.0), relevance (4.7/5.0), completeness (4.6/5.0) and clarity (4.8/5.0) (Figure 2).
Conclusions: Clinical questions bridge the working mental model of hospitalists and the data (clinical and historical) of patients they treat. In the realm of authentic clinical questions, VLRChat successfully generated answers that human evaluators of varying levels of experience noted to be highly accurate, relevant, and clear. Analysis of this preliminary dataset suggests that VLRChat could enhance educational decision support by rapidly providing users with answers grounded in a trusted and accurate resource. VLRChat may augment care by directing users rapidly to curated content of which they were previously unaware. This effect is enhanced further by the cross-cutting way in which VLRChat synthesizes content across multiple chapters of VIMBook.Timely, intuitive platforms that deliver evidence-based guidance improve the quality and safety of patient care and contribute to a Learning Health System. Following further refinement and validation based on human feedback and co-design, we plan to launch VLRChat for public use in January 2025, offering a trusted, real-time resource for bolstering clinical knowledge.