Background: Patient After-Visit Summaries (AVSs) are critical to ensuring safe and effective hospital discharge. However, these documents are often written at reading levels that exceed many patients’ health literacy, leading to misunderstanding of care instructions and preventable post-discharge complications. Hospitalists face increasing documentation burden and limited time for discharge education. Large language models (LLMs) may improve clarity and patient-centered communication, but their quality and safety in real clinical settings remain uncertain. To address these gaps, this study evaluated whether LLMs can produce higher-quality, more readable, and equally safe AVSs compared with attending physicians.
Methods: We conducted a retrospective, blinded, cross-sectional comparison of clinician-authored AVSs and LLM-generated AVSs among 50 adult patients discharged home from an attending-only hospital medicine service (January-December 2023). Encounters were limited to attending-only teams, and one hospitalization per patient was included. Fifty eligible encounters were randomly sampled. This study was deemed exempt by the UCSD IRB. The physician-written hospital course from the discharge summary was used as source text to generate an AI drafted AVS using two distinct LLMS (a HIPAA compliant Microsoft Copilot [GPT-4] and Gemma 3n 2B) using a prompt that: emphasizes patient-centered language, avoidance of jargon, tailored recommendations, and a 6th-grade reading level. Five blinded attending physicians independently evaluated AVSs using two instruments: PEMAT v2.0 (understandability and actionability) and the six-domain AVSrubric (accuracy, completeness, clarity/readability, consistency with medical record, tone/empathy including a binary potential-for-harm item). Each reviewer assessed ten unique patient charts (three AVSs per chart: clinician, Copilot, Gemma). PEMAT and AVSrubric scores were compared across the three AVS types using Mann–Whitney U tests; the binary harm measure was evaluated via Fisher’s exact test. P-values were adjusted for multiple comparisons using the Benjamini–Hochberg false discovery rate.
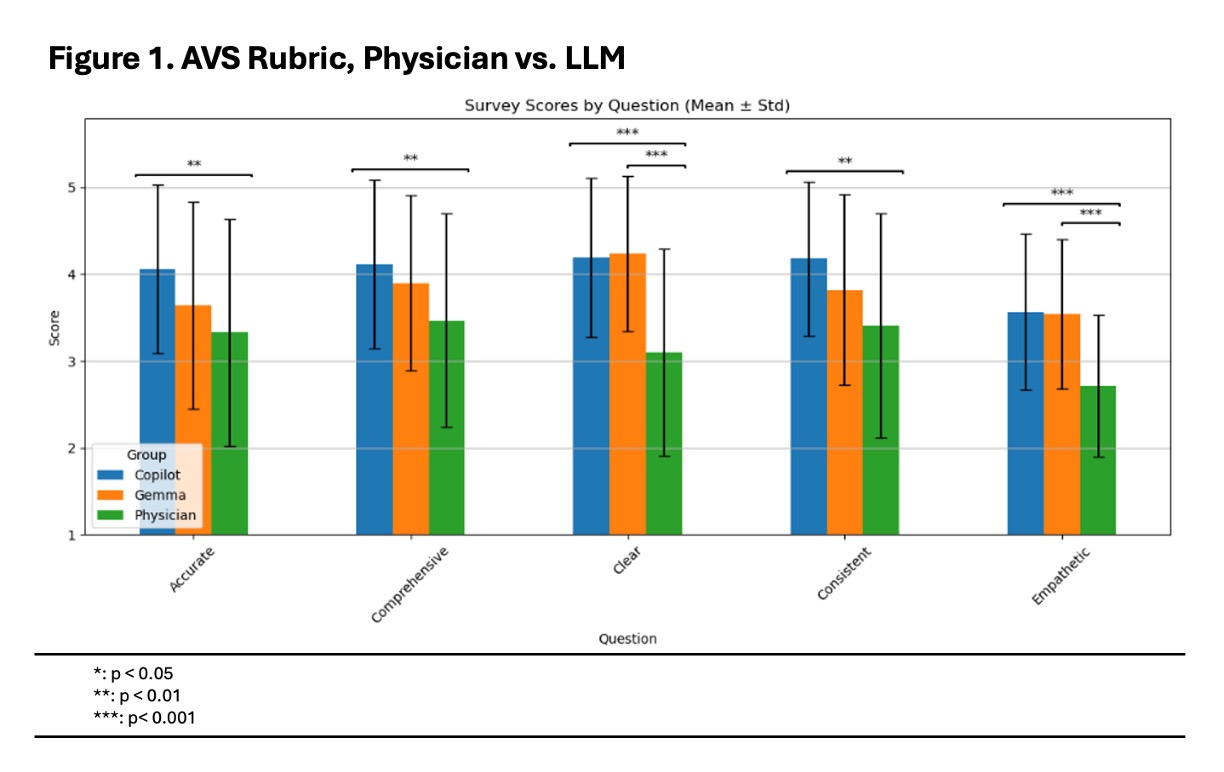
Results: Physician-authored AVSs scored 66.1% for understandability and 56.7% for actionability on PEMAT. Copilot-generated AVSs scored 85.5% and 70.9%, respectively, and Gemma-generated AVSs scored 87.5% and 74.1% (p < 0.001 AI vs physician for both models)(Table 1). On the AVS rubric, both LLM-generated AVSs outperformed physician AVSs across all domains, with the largest improvements in clarity/readability and tone/empathy (p < 0.001)(Figure 1). There was no increase in perceived potential for harm: 96% (Copilot) and 90% (Gemma) AI-generated AVSs were rated “no potential for harm” compared with 80% of physician-authored AVSs (p = 0.02 for Copilot vs physician). No significant differences were observed between the two LLM systems.
Conclusions: LLM-generated AVSs demonstrated significantly greater readability, patient-centered tone, and actionability than physician-authored AVSs, without increased risk of factual inaccuracy or harm. When used in a physician-in-the-loop workflow, LLMs may improve discharge communication quality and reduce documentation burden. Prospective evaluation of LLM-generated patient-facing discharge instructions will assess implementation, feasibility, physician time savings, and patient experience.
.jpg)