Background: To mitigate COVID-19 related hospital crowding, our hospital internal medicine (HIM) department collaborated with our emergency department (ED) to launch a service in which an HIM team was placed in the ED to assist with triage. The goal was to expedite patients with a clear need for admission, while diverting others who could be safely cared for as outpatients. Initial, unpublished results of this program were promising, suggesting that the program helped save inpatient beds for those most in need of hospitalization. To further enhance the efficacy of this HIM team in facilitating ED patient dispositions, we developed and implemented a machine-learning model that predicted the probability of an ED patient’s need for hospital admission.
Purpose: To implement a retrospectively validated machine-learning model for predicting ED patients’ need for hospital admission in a live cloud environment and investigate its performance on live data.
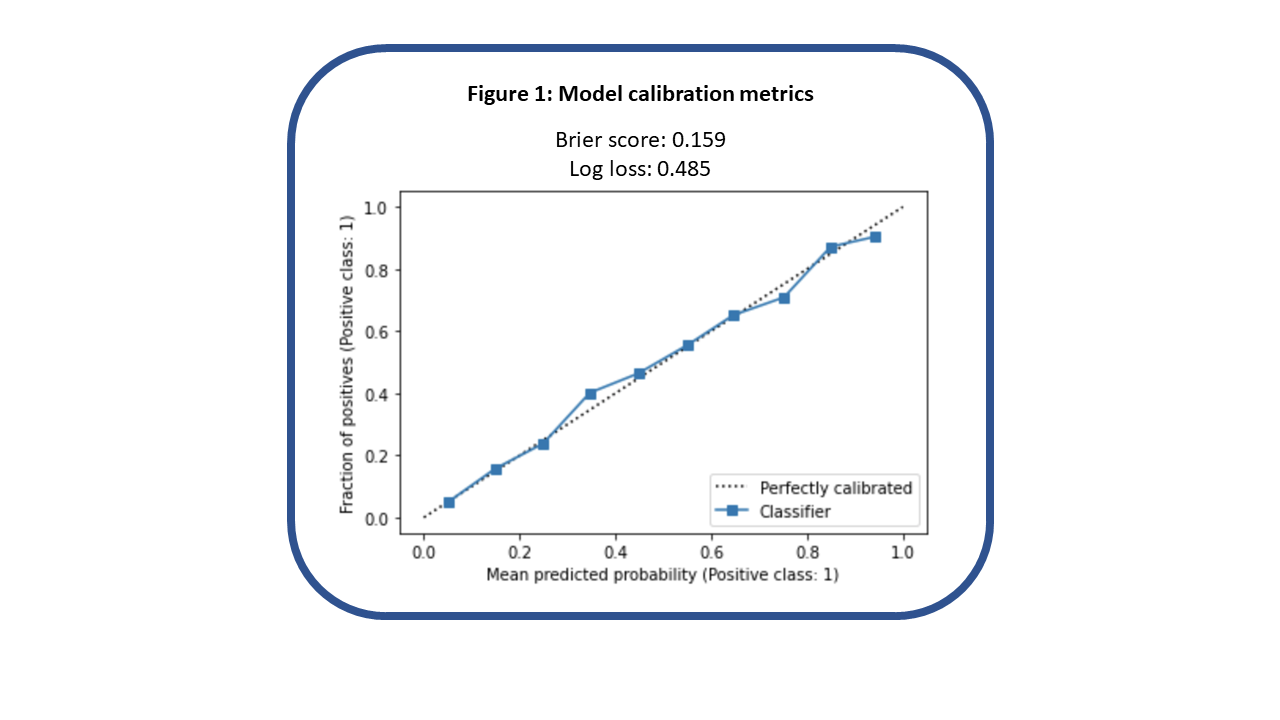
Description: We trained and validated a gradient-boosted trees machine-learning model for predicting ED patients’ need for hospital admission based on 46 factors available early in the patient’s ED course; this work was published, with the model demonstrating an area under the receiver-operator curve (AUC) of 0.88 at our health system’s largest ED. (Ryu et al, MCP-IQO, 2022) We then focused on preparing the model for live operation in our electronic health record’s (EHR) cloud environment. We discovered that doing so required us to remove certain model features that could not be recreated in this environment, such as the number of recent hospital admissions from the ED and the ED census at the time of a patient’s arrival. Fortunately, removing these features had minimal impact on the model’s performance, with AUC decreasing 0.01. After placing our model in a live testing environment, we noted significantly decreased AUC performance at 0.73, based on a two-week sample of data. Ultimately, we traced this back to inconsistencies between how certain vital signs were timestamped in the retrospective versus live data. Specifically, we noted that in some cases, “patient weight” values that were supposed to come only from values recorded in the ED were actually coming from values recorded after admission, allowing our model to more easily discern which patients got admitted. After correcting this in the retrospective data, we retrained our model and noted slightly decreased AUC at 0.83, relative to the initial model. However, once the updated model was moved into the live environment, performance closely mirrored what was achieved on the adjusted, retrospective data, with AUC 0.81, based on one month of data collection, comprising 6,143 ED visits. The calibration curve and loss scores for our model in live operation over this one-month period are shown below.
Conclusions: In the process of implementing an internally developed machine-learning model at our institution, we uncovered multiple pitfalls that may cause live model performance to differ from what was expected based on retrospective data. However, after substantial troubleshooting, our model achieved strong performance in live operation. This has enabled real-time accurate prediction of admission likelihood to strengthen the appropriate triage of internal medicine patients in the ED.