Background: Surgical co-management (SCM), a care model in which hospitalists jointly manage medically complex perioperative patients with surgical teams, has demonstrated decreases in surgical complications, decreases in length of stay, and cost savings (1-6). At Stanford Health Care (SHC), SCM physicians manually screen elective surgeries to identify patients requiring co-management services. However, this process contributes to increased time in the electronic health record (EHR) and inter-provider variability in clinical judgment. We designed, deployed, and prospectively evaluated an EHR-integrated, large language model (LLM)-powered human-in-the-loop patient screening tool to automate this workflow.
Purpose: The objectives of this study were to 1) characterize the sensitivity and specificity of a patient screening tool, 2) characterize the accuracy of the tool’s judgment against hospitalist judgment, and 3) assess the impact on hospitalist workflow
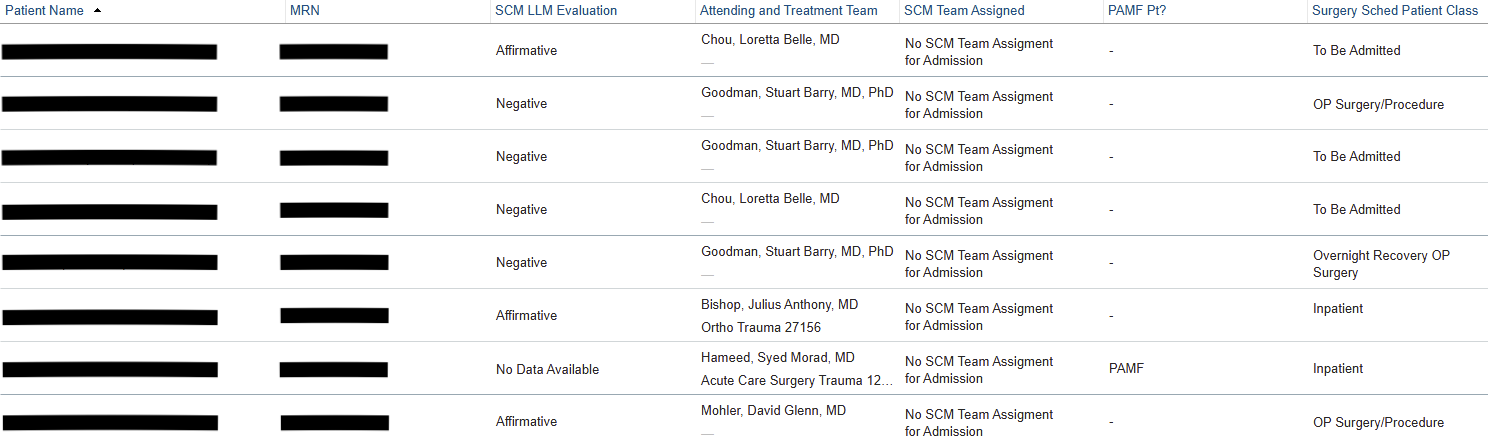
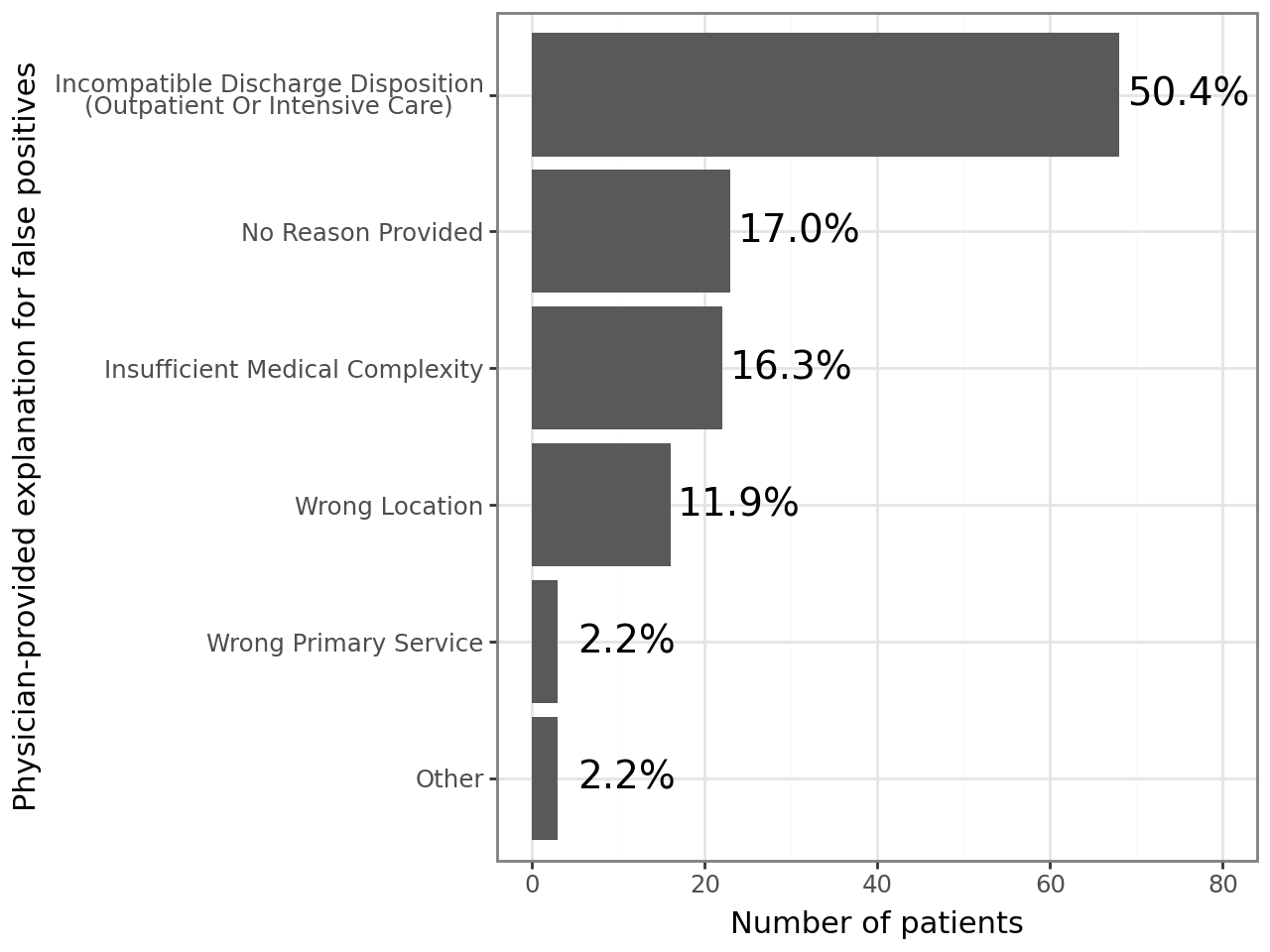
Description: The SCM screening tool is a custom LLM-powered agentic workflow built on SHC’s proprietary platform for securely deploying LLMs (7). Agents using OpenAI’s o3-mini have access to clinical criteria associated with peri-operative morbidity (8, 9) as well as each patient’s pre-operative anesthesia evaluation note. They are prompted to categorize patients as being appropriate, not appropriate, or possibly appropriate for SCM along with a brief explanation of its reasoning. The tool achieved 92% (95% confidence interval 86-96%) accuracy against SCM hospitalist consensus in retrospective validation and was deployed for real-world prospective pilot use on September 22, 2025. The screening tool’s output and reasoning are displayed via custom EHR fields to SCM hospitalists, who can indicate their agreement. 16 SCM hospitalists participated in this pilot. Baseline pre-pilot manual OR screening times were 63 minutes/day. Since pilot initiation, 2,453 surgical cases were screened by our LLM agentic workflow in real-time; 1,280 (52.2%) were recommended for SCM. Using treating physicians’ determinations as the reference standard, the agent maintained very high sensitivity for identifying patients judged appropriate for SCM (0.946, 95% CI 0.903 – 0.982); its specificity decreased to 0.414 (95% CI 0.349 – 0.475). Review of putative false-positive cases (n = 136) suggested that many (n = 83; 61.0% of false positives) represented “false flags” driven by upstream data issues—such as patients scheduled for outpatient procedures that should have been excluded from the screening population—rather than misclassification by the model. An additional 17 (12.5%) of false positive cases reflected variability in physician opinion about which patients warrant SCM consultation, indicating that some apparent disagreements arose from lack of alignment on eligibility criteria even when the agent correctly identified the risk factors specified in the prompt.
Conclusions: This novel patient screening tool highlights the potential of an LLM workflow to automate portions of clinical protocol. The tool demonstrated significant accuracy and sensitivity; lower specificity rates were likely the result of categories that could otherwise be manually eliminated from the screening population. Further investigation is needed to determine the impact on physicians’ manual screening time, time spent in the EHR overall, and the nature of false negative and false positive flags.