Background: Diagnostic reasoning is a core competency of medical training, yet opportunities for structured, hypothesis-driven clinical decision-making remain limited during clerkship years. This project expands an established mystery-case teaching series into a formalized curriculum that leverages large language models (LLMs) to enhance clinical reasoning among third-year medical students. Over the past five years, the weekly mystery case format has engaged learners in gathering history, interpreting physical exam findings, and constructing a working differential.
Purpose: The proposed curriculum scales this model into four high-yield case modules and integrates AI-supported formative assessment to individualize feedback and strengthen diagnostic competency.
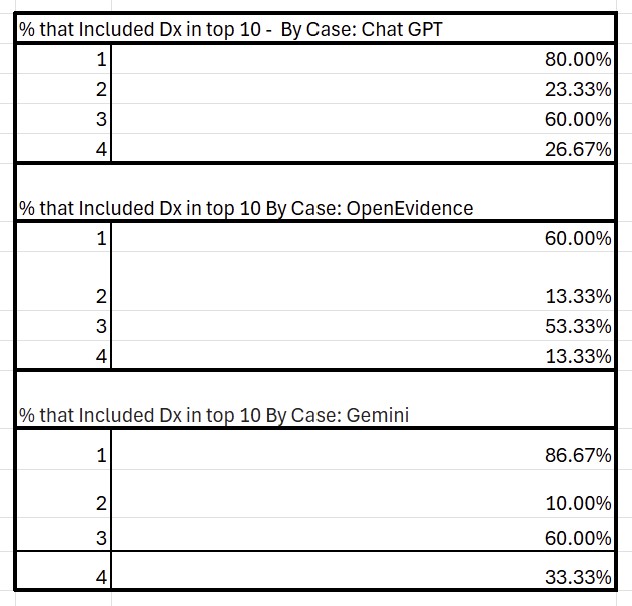
Description: During each session, students iteratively build a differential diagnosis through hypothetico-deductive questioning, targeted physical exam maneuvers, and cost-conscious ordering via a custom “lab machine” in Microsoft Excel that displays real-world test costs. Students then submit a written “Patient Representative Statement” synthesizing their diagnostic reasoning. A central innovation of this project is the incorporation of LLM’s to objectively score “Patient Representative Statements”. Each statement is processed by three AI systems to generate a ranked list of ten differential diagnoses. Students then receive a score from 1–10 based on the placement of the correct diagnosis (e.g., first = 10 points). This scoring method provides a quantitative proxy for the accuracy and completeness of each student’s clinical reasoning. When an AI model ranks the correct diagnosis highly, it suggests that the student effectively communicated the salient features and diagnostic logic. Lower rankings highlight omissions or unclear reasoning. This curriculum was piloted across 28 students over two four-week cohorts, preliminary scores varied by case and model (See Tables 1 and 2), indicating that the scoring approach meaningfully differentiates between easier and more complex cases as well as higher- and lower-quality student reasoning. However, future research is needed to validate this scoring approach across larger cohorts and additional clinical presentations, further examining how well AI-generated differentials continue to distinguish between simpler and more complex cases. By transforming subjective faculty assessment into scalable and real-time feedback, this AI-supported scoring approach can enable students to identify reasoning gaps.
Conclusions: The curriculum is intentionally sustainable: it requires minimal preparation using standardized case guides, cloud-based diagnostic tools, near-peer facilitation, and automated LLM scoring. Future research should explore how schema-based instruction, combined with AI-supported assessment, influences long-term retention of diagnostic skills and performance in real clinical settings. Additionally, further study plans to integrate an AI agent to work individually with students on a pre and post curriculum case to evaluate growth in “Patient Representative Statement” formation.
.jpg)