Background: Current surveillance approaches underestimate harmful diagnostic errors (DE) in hospitalized patients. A recent study of 2809 admissions observed that while one or more adverse events (AE) occurred in 23.6% of cases, only 10 AEs (0.1%) were attributable to DEs (1). Studies using the Safer Dx instrument have observed harmful DE rates of 5-7% (2). We previously identified DE risk factors and developed an electronic health record (EHR)-embedded prediction algorithm to calculate DE risk during hospitalization (3, 4). In this prospective study, we assessed the algorithm’s performance to predict cases with DEs.
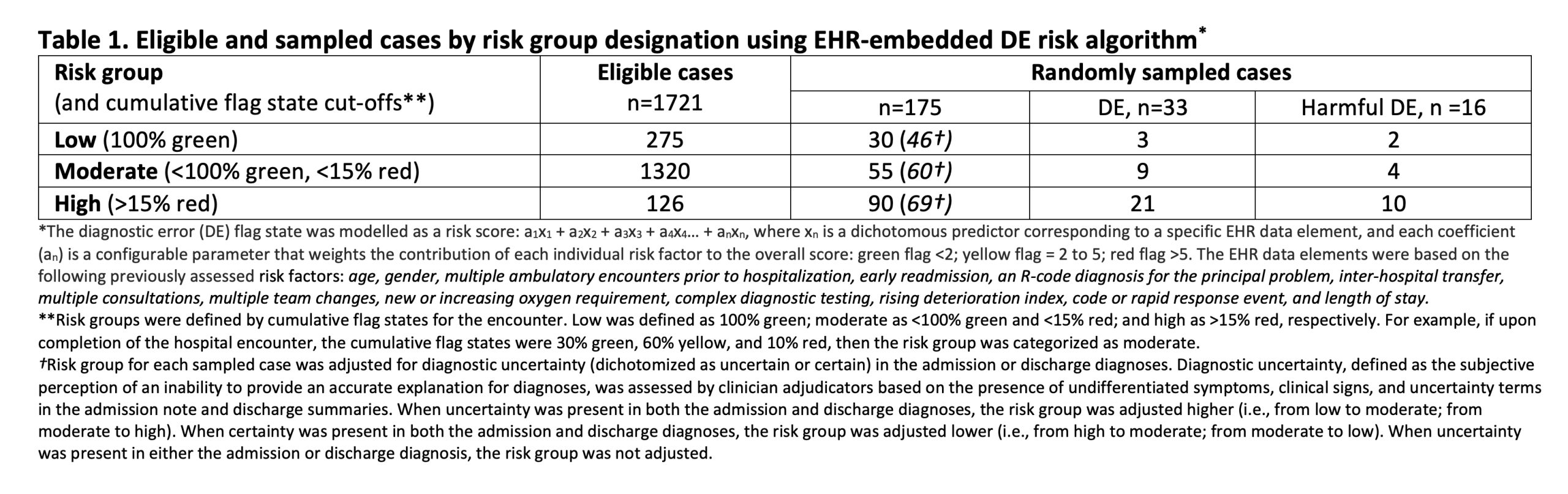
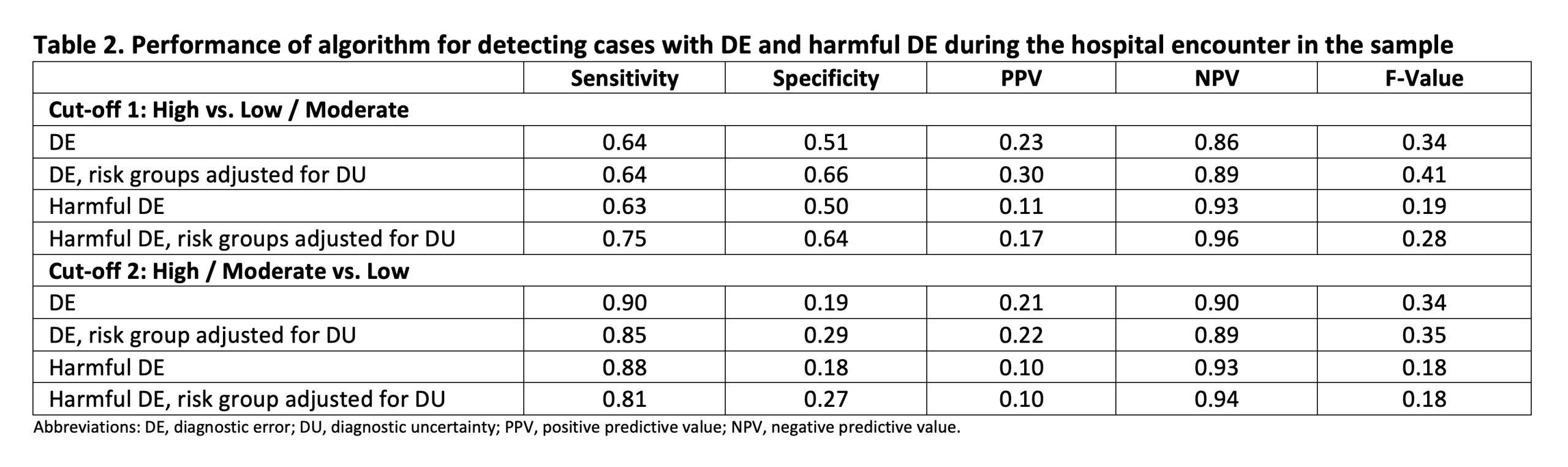
Methods: Eligible cases on general medicine service at a community hospital in Boston, MA were prospectively identified from 7/2022 to 12/2022. The algorithm ran in the background and calculated the flag state (a measure of being at risk for DEs) at 15-minute intervals using selected EHR data (Table 1) retrieved in real-time. The percentage of time the flag state was green, yellow, or red during the encounter was used to categorize cases into 3 risk groups (low, moderate, high). High-risk cases were randomly oversampled to ensure adequate representation. The risk group for each case was adjusted higher (or lower) based on the presence of diagnostic uncertainty (or certainty) in the admission or discharge diagnoses. Diagnostic uncertainty (DU), likelihood of DE (using the Safer Dx instrument), and associated harm, were independently assessed by 2 expert clinician adjudicators. Weighted estimates of DEs and harmful DEs in the population were calculated. The sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) for DEs and harmful DEs were calculated before and after adjusting risk groups for DU using two risk group cut-offs (high vs. moderate/low and high/moderate vs. low).
Results: Of the 1721 eligible cases, 126 (7.3%), 1320 (76.7%), and 275 (16%) were categorized as high, moderate, and low risk (Table 1). The 175 randomly sampled cases (30 high, 55 moderate, and 90 low risk) had the following characteristics: age, mean 66.0 years (SD, 17.8); female, 111 (63.4%); White non-Hispanic, 116 (66.3%), Black non-Hispanic, 25 (14.3%), Hispanic, 26 (14.9%); length of stay, mean 6.5 days (SD, 4.3). Thirty-three (18.9%) DEs and 16 (9.1%) harmful DEs were identified, corresponding to population weighted estimates of 12.5% and 7.5%, respectively. Using the high vs. moderate/low-risk cut-off, the sensitivity, specificity, PPV, and NPV for harmful DE were 0.63, 0.50, 0.11 and 0.93, respectively. When risk groups were additionally adjusted for DU, these measures changed to 0.75, 0.64, 0.17, and 0.96, respectively. Similar analyses were conducted for all DEs (not just harmful), and by using the high/moderate vs. low cut-off (Table 2).
Conclusions: In a prospectively sampled population with low prevalence of harmful DEs, an EHR-embedded risk algorithm demonstrated low PPV but high NPV for detecting these errors. This EHR-based screening approach may have value for excluding cases without harmful DEs, leaving a smaller, enriched cohort with harmful DEs. These cases can then be reviewed using the validated Safer Dx instrument, which has been demonstrated to have a higher PPV (2). The incorporation of DU as a variable will likely improve the algorithm’s performance. This is encouraging, especially with recent advancements in large language models, which can be trained to not only gauge DU but also discover other previously unidentified DE risk factors in this population.