Background: Health systems are rapidly piloting Large Language Model (LLM)-enabled tools within the Electronic Health Record (EHR) [1–4], but there is limited guidance on how to evaluate these tools during early deployment [5]. Qualitative clinician feedback is essential for understanding real-world usability, identifying safety concerns, and guiding iterative improvement of novel technologies [6]. Traditional qualitative research methods for synthesizing narrative feedback are resource-intensive and difficult to scale [7], limiting their usefulness for rapid iteration and governance.
Purpose: We developed and applied a mixed-methods evaluation framework while piloting a novel inpatient artificial intelligence (AI) chart review tool, combining structured ratings with an LLM-assisted pipeline for high-throughput quantitative thematic analysis of free-text clinician feedback.
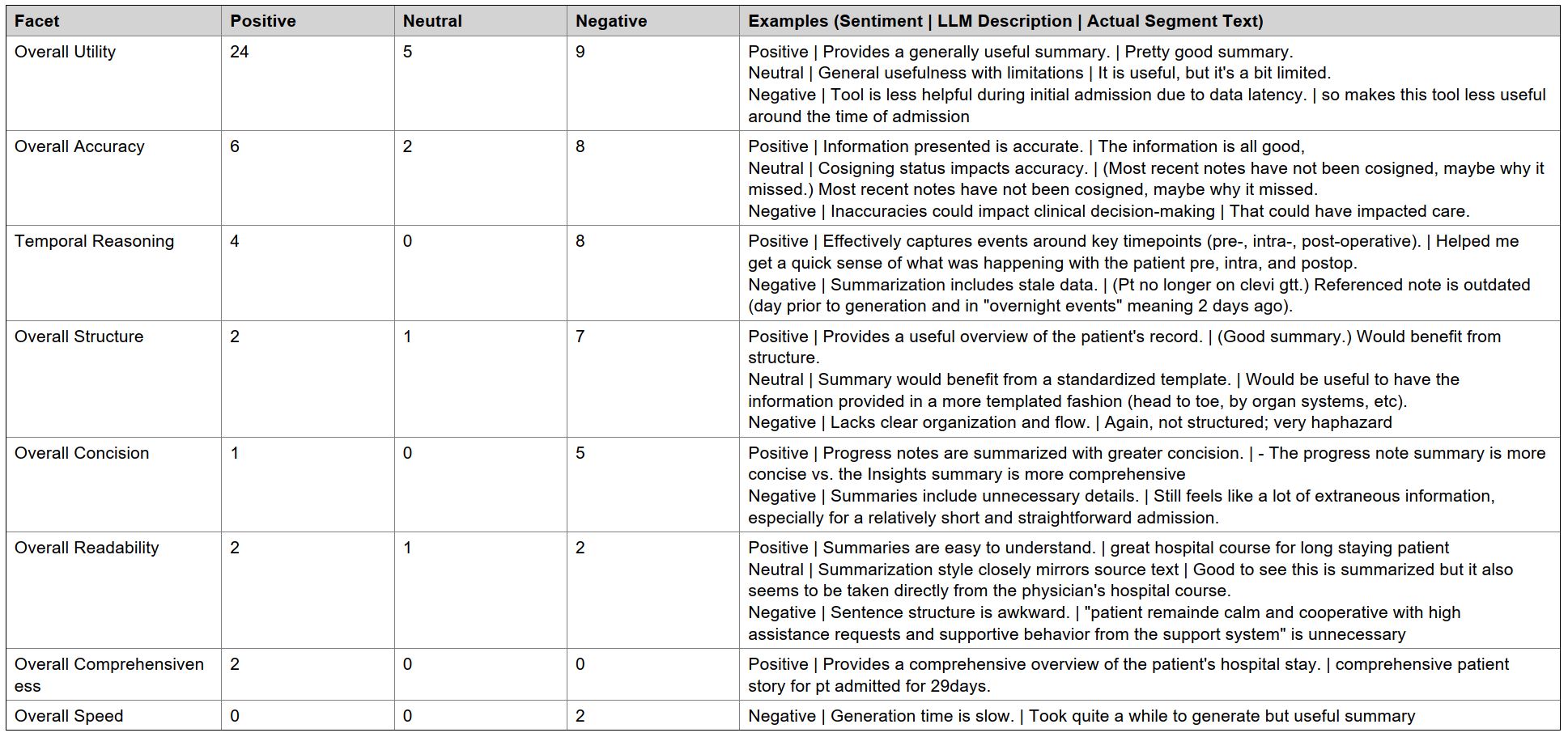
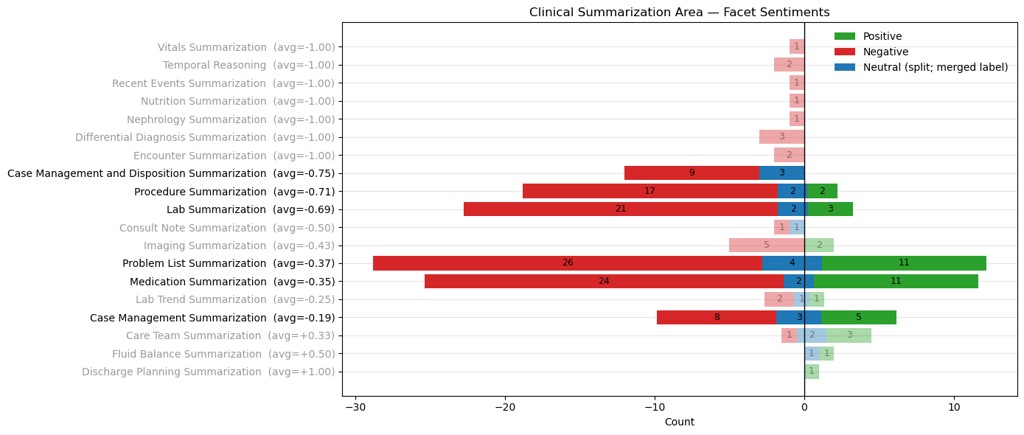
Description: The EHR-integrated inpatient AI chart review tool was piloted with a small group of clinicians from 7/4/2025 through 9/5/2025. Structured and narrative feedback was solicited for all generated summaries. Free-text feedback was analyzed using a custom LLM pipeline that first segmented narrative comments into discrete units and then applied mixed deductive/inductive labeling and sentiment classification. High-level feedback categories (summative, task-specific, and feature-specific) were defined by the implementation team, while low-level codes were generated inductively via LLM labeling using prompts refined through iterative physician review. An open-source, locally hosted LLM (gemma-3-27b) was used for accessibility and generalizability.26 clinicians participated in the pilot (21 physicians/advanced practice providers, 3 nurses, and 2 case managers). Participants generated 783 summaries across three summary types. 172 summaries received structured feedback with107 (62%) labeled “helpful without errors.” When errors were present, the most frequent category was inaccurate/omitted information (31/65 = 48%). Free-text feedback was provided for 124 summaries, which were segmented by the LLM into 331 discrete segments (mean 1.9 per summary). A total of 44 inductive codes were generated in the 3 high-level categories: 8 summative, 19 task-specific, and 17 feature-specific. Example labels and analysis are provided in Table 1 and Figure 1 for segments classified as summative feedback.Sentiment regarding overall utility was predominantly positive (24/37 labels = 65%), consistent with structured ratings. Task- and feature-specific codes highlighted strengths in care team summarization (3/6 positive labels = 50%) and the citation feature (7/11 positive labels = 64%), alongside clear opportunities for improvement in tasks such as lab summarization (21/26 negative labels = 81%), and features such as date timestamps (6/6 negative labels = 100%).
Conclusions: A mixed-methods framework anchored by LLM-assisted thematic analysis can transform large volumes of clinician free-text feedback into structured, quantitative signals. For the inpatient AI chart review tool, this approach identified both strong perceived utility and specific, actionable areas for enhancement, aligning with and extending structured rating data. More broadly, LLM-assisted thematic analysis offers a scalable approach for health systems to transform narrative clinician feedback into actionable insights that can guide iterative improvement and responsible evaluation of novel technologies and processes.