Background: Diagnostic uncertainty, defined as the subjective perception of an inability to provide an accurate explanation of the patient’s health problem, has been implicated in diagnostic error.1 Clinician notes, such as the admission notes, often include hedging terms, uncertainty phrases, and diagnostic differentials that can be used to assess uncertainty in unstructured documentation.1,2 Quantifying diagnostic uncertainty from notes has multiple benefits, such as modeling DE risk early during hospitalization and triggering electronic health record decision support. The rise of large language models (LLMs) and generative AI tools (e.g., ChatGPT) presents a novel approach for assessing diagnostic uncertainty in unstructured documentation but requires validation. In this study, we sought to compare LLM to human-assessed evaluation of diagnostic uncertainty in admission notes.
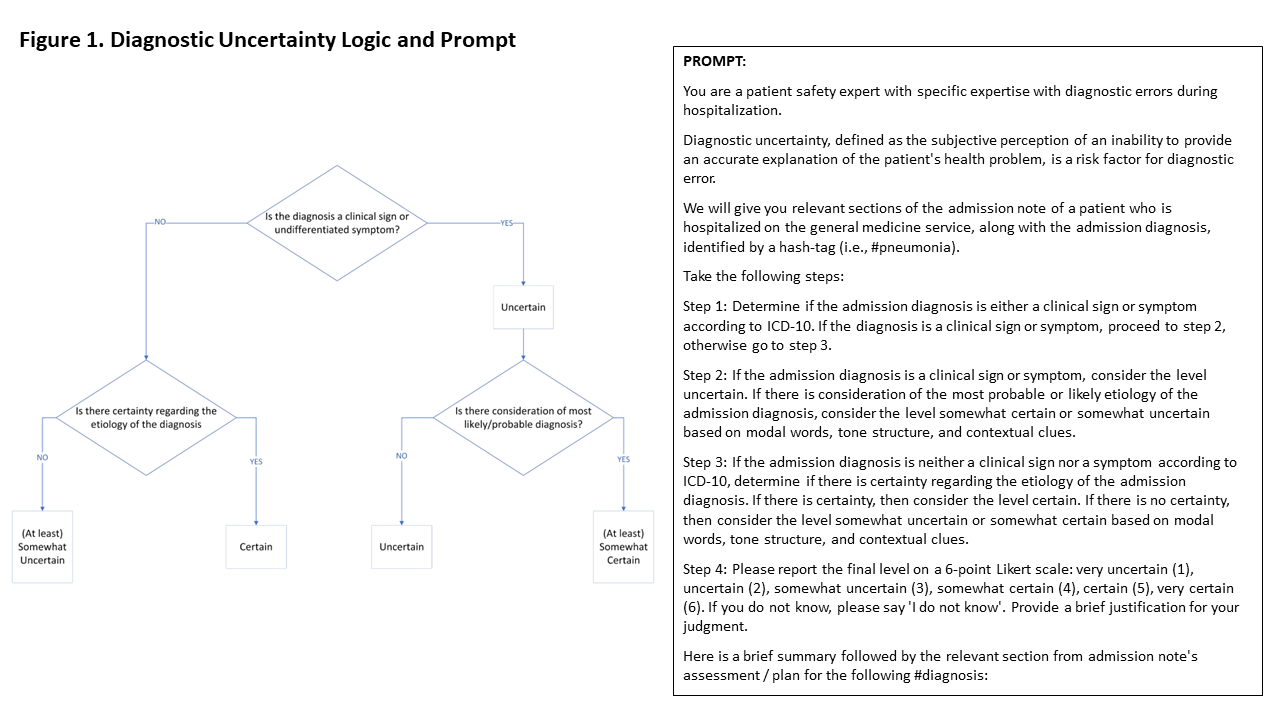
Methods: We defined a “gold-standard” assessment of diagnostic uncertainty based on the presence or absence of clinical signs or symptoms (ICD-10 “R” codes) for the admission diagnosis, and either the presence of uncertainty regarding the etiology of that diagnosis or consideration of the most probable diagnosis (Figure 1 ). Using this definition, we conducted a secondary analysis of 174 cases in which 2 clinicians independently assessed and rated diagnostic uncertainty in admission notes on a 6-point Likert scale. All discrepancies were resolved by consensus and confirmed by an expert panel, an approach that has yielded strong agreement (Kappa >0.7) between the expert panel and consensus reviews.3 To interact with ChatGPT, we iteratively developed a prompt (Figure 1) to perform prespecified actions to rate the level of uncertainty modeled like the manual process. ChatGPT, accessed in a HIPAA compliant environment (Microsoft Azure), was provided unaltered text from the admission note (brief summary; first listed problem, in assessment/plan, including rationale, diagnostic testing, and treatments) as a system message along with user-generated examples. The temperature was set to zero. Descriptive statistics were used to report distribution of Likert ratings from consensus review and ChatGPT. Interrater reliability (Cohen’s Kappa) between ChatGPT and consensus review, and ChatGPT versions 3.5 and 4 was calculated using dichotomized Likert ratings (certain vs uncertain).
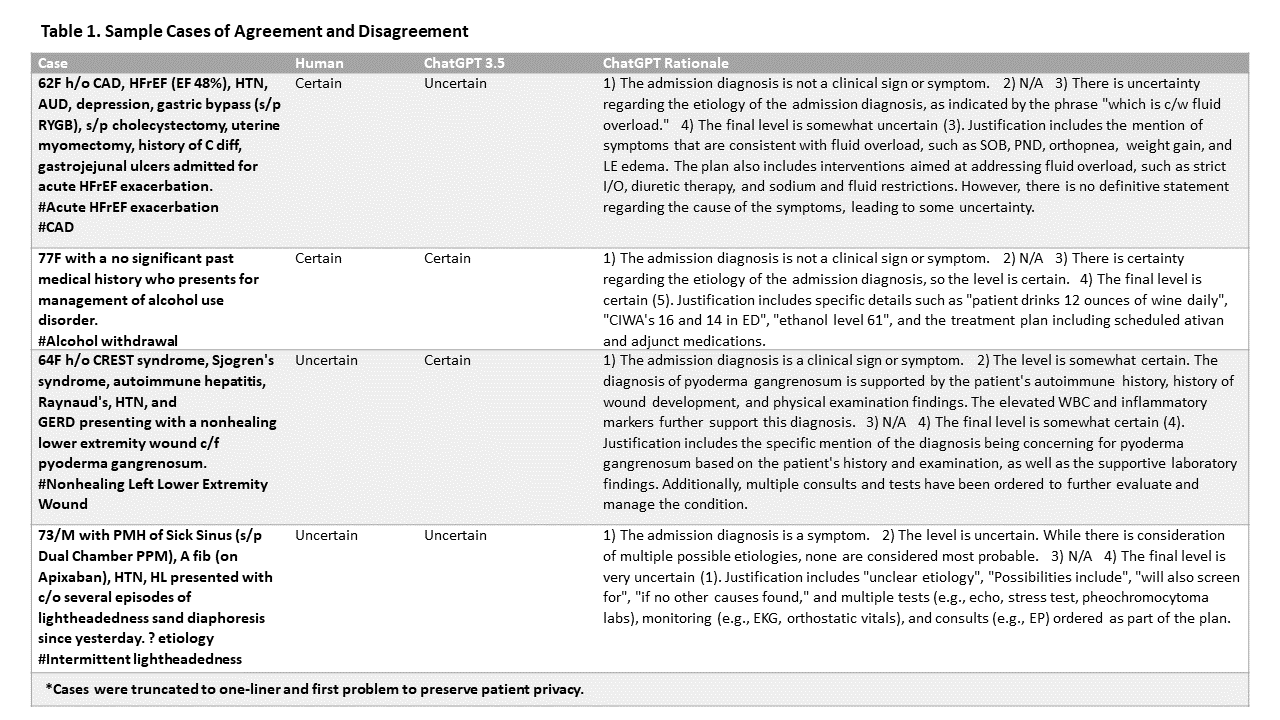
Results: The means (SD), medians (IQR), and modes were 3.25 (1.65), 3 (3), and 4 for human reviews; 3.1 (1.38), 3 (2), and 2 for GPT 3.5; and 4 (1.50), 4 (3), and 4 for GPT 4, respectively. Cohen’s Kappa was 0.48 (p< 0.001) between ChatGPT 3.5 and human review (129 agreed, 45 disagreed; 74.1% agreement), and was 0.44 (p < 0.001) between ChatGPT 4 and human review (124 agreed, 50 disagreed; 71.3% agreement). For each case, ChatGPT also provided a rationale for its rating (Table 1).
Conclusions: We observed moderate interrater agreement between ChatGPT and human assessment of diagnostic uncertainty in admission notes using our gold standard definition. These finding may be explained by differences in content assessed by clinicians vs GPT (ChatGPT was only provided specific sections of the assessment and plan), or the interpretation of the gold standard definition for diagnostic uncertainty by clinicians vs GPT. Further prompt iteration and consistent interpretation of the gold standard definition would be required prior to using ChatGPT to assess admission notes or serving as a cognitive aid in the diagnostic process.