Background: Large Language Model (LLM) chatbots, like ChatGPT (from Open-AI), have received widespread attention in the last year for their ability to process large amounts of text data and produce human-like script responses on a wide array of topics. In particular, LLM chatbots have performed well in areas of patient communication, whether it’s answering cardiovascular disease questions, public health questions posed to an online forum, or drafting outpatient provider inbox responses. In Hospital Medicine, crafting patient discharge instructions is an important, albeit time consuming process, and pre-existing templated instructions are of varying quality without any individualized patient information. In this study, we evaluated the ability of ChatGPT to craft personalized patient discharge instructions using information from Hospital Medicine discharge summary notes.
Methods: De-identified Hospital Medicine discharge summaries were selected at random from the MIMIC-IV database. Initial GPT-4 prompts were engineered to define the general structure of discharge instructions. We input the entire hospital course section from 15 discharge summaries into ChatGPT via the secure and approved Azure API per the PhysioNet Data Use Agreement. The generated discharge instructions were evaluated by two hospital medicine physicians for accuracy (5-point Likert scale with 1 containing completely incorrect information and 5 containing all correct information) and general quality (5-point Likert scale, with 1 being very poor quality and 5 being very good quality). We then calculated the Flesch-Kincaid Readability Grade-Level metric for each discharge instruction. Scores were evaluated using descriptive statistics.
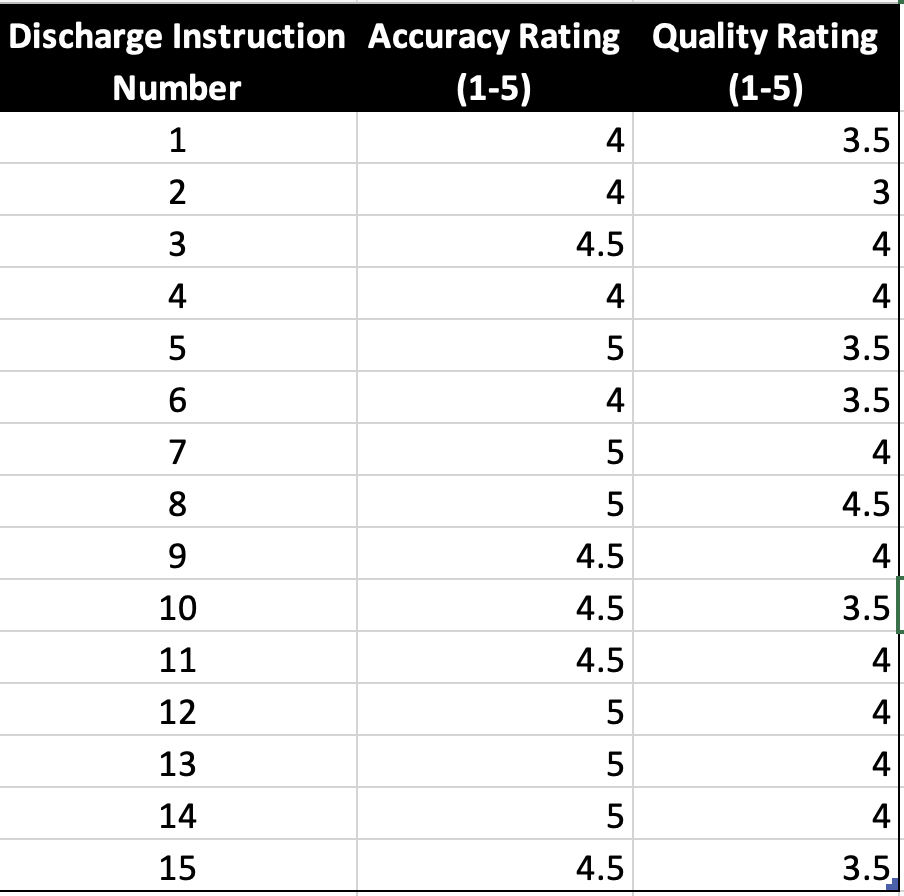
Results: Across the 15 AI-generated patient discharge instructions, the mean accuracy score was 4.57 (SD 0.496, CI 4.39 – 4.74). The instructions were given a mean quality score of 3.8 (SD 0.476, CI 3.63 – 3.97). The average readability grade-level of ChatGPT’s responses were near the 6th grade reading level, with a mean grade-level of 7.01 (SD: 1.07, CI: 6.55 – 7.47).
Conclusions: In this cross-sectional study, ChatGPT successfully generated Hospital Medicine patient discharge instructions using real discharge summaries and they were rated as generally accurate and of moderately high quality. The instructions were personalized to the patient and were at a reading level appropriate for the general public. Further exploration of the use of this technology in the inpatient setting is warranted and may in the future improve physician workflow.